嗯,这个世界已经阻止不了程序猿了......
人机验证简介
人机验证(Captcha,全自动区分计算机和人类的公开图灵测试)是一类进行问答式身份验证的安全措施,目标是区分正常用户操作和计算机程序访问,从而差别处理以实现对系统的保护。
在Captcha测试中,作为服务器的计算机会自动生成一个问题交由用户来解答。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于计算机无法解答Captcha的问题,所以回答出问题的用户就可以被认为是人类。

人机验证的必要性
随着网络的发展,大量计算机系统实现了互联。互联在给我们提供便捷的同时,也使得计算机程序时刻面临着各种各样的威胁,一旦被攻击,将会造成非常大的损失,因此程序的安全性变得十分重要。
比如接口枚举攻击就是常见的攻击类型。接口枚举攻击是指非法程序对正常接口在短时间内进行大量请求。
有时是对一次请求的重放,导致正常用户无法访问该接口或访问缓慢,属于拒绝服务攻击(DoS)的一种形式;有时是对接口请求参数进行枚举,试图破解安全防御,比如登录场景下,对登录密码进行枚举试错;有时是恶意消耗资源,比如对短信发送的接口进行攻击实现短信轰炸。

这些都属于高频率的异常访问,人机验证就是一种识别并阻止这类访问的安全机制。人机验证技术有助于保护系统免受垃圾信息、恶意注册的干扰,使系统运行更加安全。
常见的人机验证模式
传统的人机验证方法是利用图形的视觉识别来进行验证,常用验证方案有:图片字符验证、图片含义验证、上行短信验证。
验证码技术的使用非常广泛,比如,一个用户进行登录操作,连续几次都输错密码,将会提供验证码让其输入答案,这样可以防止对登录操作做暴力破解。但验证码在提供安全机制的同时,会影响用户体验,近年来对验证技术的改进主要集中在不降低安全性的同时提高用户体验。

第一代验证模式被称为标准验证模式,也是我们最常见的图形验证码、语音验证码。其原理是基于机器难以处理复杂的计算机视觉及语音识别问题,而人类却可以轻松的识别来区分人类及机器。
这一代验证码初步利用了人类知识容易解答,而计算机难以解答的机制进行人机判断。为了降低机器对图形的识别概率,往往会在生成的图片中加入干扰项。最早期的验证码,使用扭曲的字母和变化的背景颜色梯度来防御图像分析。
后来,一种更现代的验证码,不使用扭曲的背景及字母,而是增加一条曲线来使得图像分析更困难。另一种增加图像区分难度的方法为是将符号彼此拥挤在一起,但这也使得真人用户比较难以识别。
第二代验证模式被称为创新验证模式,是基于第一代验证码的核心思想(通过人类知识可以解答,而计算机难以解答的问题进行人机判断)而产生的创新的交互优化型验证码。

第二代验证码基于第一代验证码的核心原理--“人机之间知识的差异”,拓展出大量创新型验证码,比如:加减乘除数学算式型的验证码、知识问答验证码等。大名鼎鼎的12306 网站所使用的验证码也属于此类。
第三代验证模式,即无知识性验证模式。其最大的特点是不再基于知识进行人机判断,而是基于人类固有的生物特征以及操作的环境信息综合决策,来判断是人类还是机器。无知识型验证码最大特点即无需人类思考,从而不会打断用户操作,进而提供更好的用户体验。
人机验证框架设计
对于人机验证的过程,我们可以抽象为3个阶段:识别➡️ 触发➡️ 验证。
识别阶段:获取每次请求的当前信息和历史信息,根据预定义规则,决定验证机制是否被触发。
触发阶段:拦截正常业务逻辑执行,根据环境上下文信息不同,生成不同类型的验证码,如字符型验证码,短信验证码等。
验证阶段:用户输入验证答案后,进行比对,决定是否对该操作放行进入正常业务处理。也可能提升风险等级后,触发更高级别验证机制。
框架在考虑功能性需求的同时,因人机验证组件在使用场景上,往往是独立于正常业务逻辑模块的,因此要兼顾到开发人员使用人机验证组件时,对原有业务逻辑无侵入,做到应用透明。下图是一个典型的人机验证框架处理过程:

框架说明:
操作2,3表示,拦截请求模块从Redis数据库中读取请求的历史信息,以判断是否需要触发人机验证。
操作11,12表示,拦截请求模块要求二次验证模块,向验证码服务模块发起二次验证,以判断客户端是否通过人机验证,以及是否符合人机验证的安全级别。
接口异常访问的识别方法
人机验证机制主要针对的就是高频率的异常访问,因此判定高频率异常访问的规则如下,如果IP地址A在T秒内对接口B的访问次数超过N次,就触发人机验证。
假设给定的场景如下(后面介绍中三个示例都基于该场景):IP地址A在60秒内对接口B的访问次数超过120次为异常访问。
本文中,我们使用Redis来存储计数信息。Redis是Key-value类型的内存中的数据结构存储系统,即Value可以是多种类型的数据结构,如String,List,Hash。Redis还可以给Key设置过期时间,时间到了,Key和Value就会被清除。
对于Key的设置来说,3种不同方法采用同一个模式,可以根据IP地址A + 访问的方法B的名字(或者访问的URL+HTTP方法)设为Key,该Key对应的Value专门用于记录IP地址A对方法B的访问历史记录。
但是不同方法,对于Value和有效期的设置,则不同。

嗯......你在说什么?(扶额)
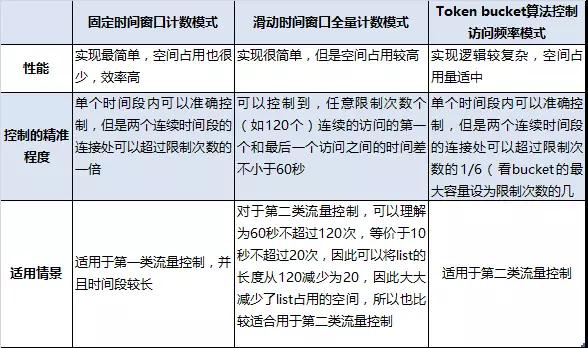
识别方法1 – 固定时间窗口计数模式
用Redis来存储固定时间窗口内的访问总数:
Value的设置:可以认为Value是正整数,代表访问次数
有效期设置:Key的有效期设为时间窗口的大小,例如示例中的60s
每次访问时,先判断Key是否存在,当Key不存在时(第一次出现或已经过期),创建一个新Key,并将对应的Value设为1,表示已经访问1次,同时设置该Key的过期时间为60秒;当Key已经存在时,取出Key对应的Value值,如果Value已经等于120,则拒绝访问或触发验证码;如果Value小于120,则允许访问并给Value加1。
算法流程图如下:

算法性质:
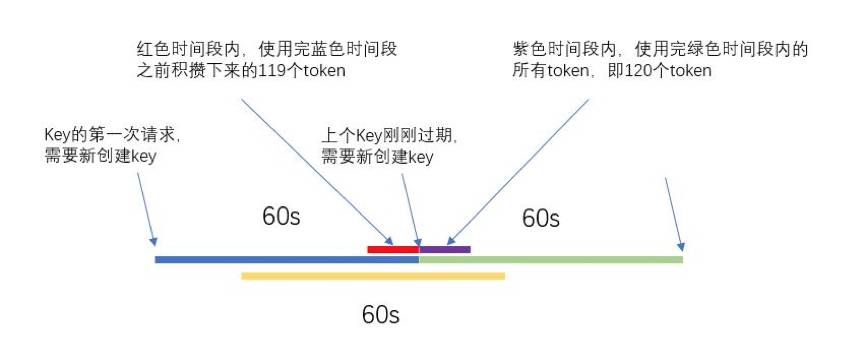
如上图所示,虽然在蓝色时间段和绿色时间段内,访问次数都不会超过120次,但是该算法的缺点是在两个连续的时间段的连接处,可以在短时间内(红色时间段加紫色时间段)达到239次的访问量,因此在黄色线段代表的时间段内访问量达到了239次,远超过限制的120次,这显然不是我们想看到的。
识别方法2 – 滑动时间窗口全量计数模式
用Redis来存储每次访问的时间:
Value的设置:可以认为Value是List,List的大小始终不大于120
有效期设置:不设置有效期
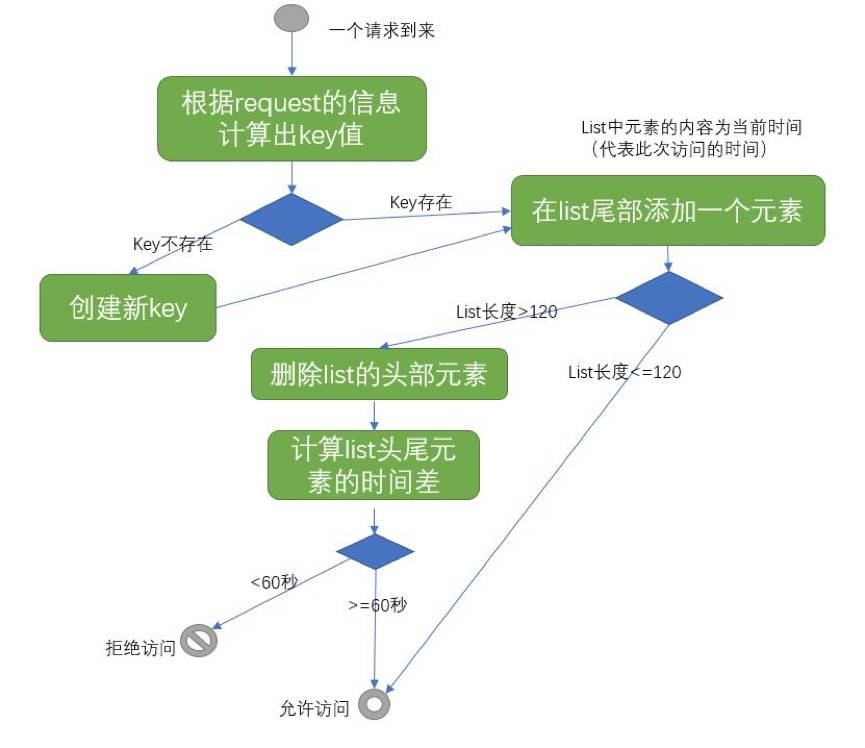
每次访问时,先判断Key是否存在,当Key不存在时(第一次出现),创建一个新Key,并在对应的空的List右侧增加一个元素,该元素记录此次的访问时间,该Key不设置过期时间;当Key已经存在时,得到Key对应的List的长度。
如果List的长度小于120,则在List的右侧增加一个表示此次访问时间的元素;如果List的长度等于120,则在List的右侧增加一个表示此次访问时间的元素,并删除List左侧的第一个元素,然后判断List最左侧和最右侧两个元素的时间差,如果时间差大于60秒,则允许访问,如果时间差小于60秒,则拒绝访问或触发验证码。
算法流程图如下:
算法性质:

该算法记录的是每次访问的时间,因此可以精确保证任意的连续120次访问,其中的第1次和第120次的时间间隔都不会少于60秒。
识别方法3 –Token Bucket算法控制访问频率模式
简单来看,可以将这个算法类比成有一个水龙头以固定的速度在不断地往一个水桶中放水,然后不断地有水瓢到这个水桶中打水去浇花,如果水桶中没水了,就不能浇花了。
如果水桶的水满了,那么水就从水桶中溢出了。在这里,水桶就相当于Bucket,水就相当于Token,水瓢取水就相当于从Bucket中取出Token。下面是原始的Token Bucket算法:
原始的Token Bucket算法概述:
1. 如果一个请求可以从Bucket中获得一个Token(即Bucket中的Token数量大于等于1),则请求放行,并将Bucket中的Token数量减1;如果Bucket中Token数为0或者Token数小于1,则请求被拒绝;
2. Bucket有最大容量,Bucket有一个初始的Token数;(可以为0,或者为小于最大容量的一个值)
3. 会以一定的速率不断向Bucket中添加Token,如果在Bucket中的Token数量等于最大容量,而且没有Token消耗时,新的额外的Token会被抛弃。

对于原始的Token Bucket算法,由于要以一定的速率均匀地向Bucket中添加Token,所以初步的实现想法是为Bucket设置一个定时器,每过一个时间间隔,就向这个Bucket中添加一定数量的Token。
但是这样的实现方式在现实中基本没办法用,原因在于,这种算法要给每个Bucket添加一个定时器,一个定时器就是一个线程,而在人机验证中往往会存在多个Bucket,Bucket的数量就等于访问服务器的用户数量,这就会使得定时器占用服务器的很多资源。

于是就有了下面的改进算法,来替代定时器这种实现方式。
用Redis来存储访问历史记录:
Value的设置:可以认为Value是一个有四个属性的Java对象,分别为:Capacity(表示Bucket的最大容量),Rate(向Bucket里面添加Token的速率,单位是个/秒),lastAccessTime(表示上一次访问的时间)Count(表示对应lastAccessTime时候Bucket中的Token数量)
有效期设置:Key的有效期设为60秒
改进算法详细说明:
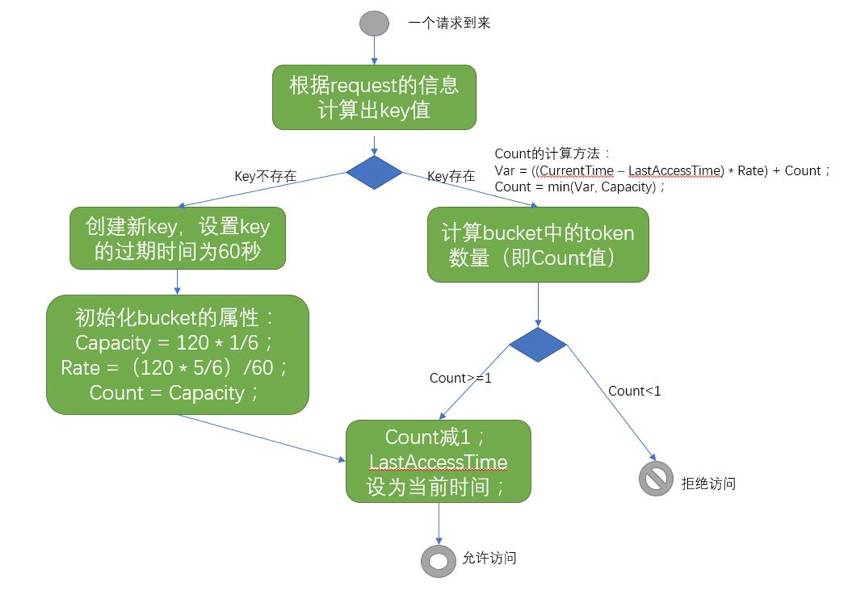
1. Bucket的最大容量设为(120个 * 1/6);
2. 当一个Key不存在时(第一次出现,或者已经过期,Key的过期时间为60秒),新创建一个Key和Bucket,将Bucket的初始容量设置为Bucket的最大容量,然后将Count值减1(本次请求消耗1个Token);
3. 添加Token的速率为(120个 * 5/6)/ 60秒,使得在这个Key的生存周期内最多得到的Token数为(初始容量 20 + 生存周期60秒内加入的Token数100)120,满足60秒内不超过120次的要求;
4. 将初始容量设置为120 * 1/6 是为了应对突发的高频率请求;
5. 如果将初始容量设置为0,然后在Key的生存周期内以120个/60秒的速率添加Token的话,无法应对60秒的前小段时间的持续高频率请求(比如前2秒以4次/秒的频率发起请求,后续就不再发起请求,具有这样特征的请求应该是合理的,不应该被马上拒绝),这样的用户体验并不友好;
算法流程图如下:
算法性质:
1
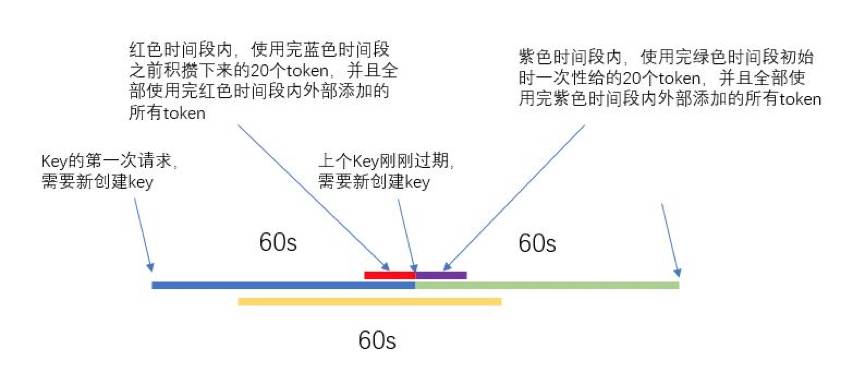
如上图所示,蓝色线段和绿色线段表示两个连续的时间段,在这两个时间段(60秒)内,访问总次数最多为120次(因为一共就往Bucket中添加120个Token),理论上应该是对任意的60秒内,访问次数不超过120次。
如果实现为滑动窗口,则可以更准确地控制访问次数,但是由于滑动窗口很难实现,只能用这个Token Bucket算法的变种来代替实现。
2
与对访问次数计数的方法一样,这个算法也会在两个连续时间段的连接处出现超次数访问的情况。
对于红色时间段,可以使用蓝色时间段之前积攒下来的Token,但是由于Bucket的最大容量就为20,所以最多积攒20个Token;对于紫色时间段,可以全部使用绿色时间段初始时的20个Token,在黄色线段对应的时间段内,外部添加的Token数为(120个 * 5/6)。
因此,黄色时间段内的Token总数为(120个 * 7/6),仅超过限制次数120次的1/6,相比于对访问次数计数的方法,超过限制次数的一倍,Token Bucket超过的次数还算可以接受。
3
该算法设定Bucket的最大容量等于Bucket的初始容量,因此如果最大容量设为限制次数的1/8,则黄色时间段内的最大访问次数可以达到限制次数的9/8。
最大容量的设定需要在应对突发高频率访问的能力和两个连续时间段连接处超过限制次数的多少,这两者之间权衡。

比较与结论
不同的流量控制算法有不同的适用情景,需要考虑到算法性能,流量特征,使用目的等多方面因素。流量控制有两类:
1. 第一类像web service对调用次数的控制,比如一天24小时免费调用不超过100次,这类流量控制更关注的是一天内实际访问的总次数,而不太关注访问的时间段,以及访问时间段内的访问频率;
2. 另一类就像人机验证对访问频率的控制,虽说判定异常流量依据的规则是60秒内访问次数不超过120次,但是,这只是衡量访问频率的一种表示方法,可以理解为平均访问频率为2次每秒,因此更关注的是访问时间段内的访问频率,而不是60秒内的访问次数到底是多少。
下面就以上提到的三种算法进行比较分析:
看完的同学,今天给自己加个鸡腿吧🍗!
作者简介:兴业数金研究开发总部 吴晓岩、侯响响、杨益明

